为什么每天要对网站进行分析呢?这样的分析有什么好处?每天对网站进行分析,可以让网站维护人员很好知道网站的健康状况,搜索引擎蜘蛛每天来网站的爬取情况,爬取了哪些页面,爬取了哪些栏目,爬取了哪些内容,什么时间过来爬,还有爬取页面的时候返回了什么样的状态码,这些东西都是可以显示网站情况的健康与否。网站维护人员可以针对这些信息,采取相应的措施来对网站进行维护更新。
做网站分析有这么多的好处,作为网站维护人员,通过什么对网站进行分析呢?那些分析数据如何才能获取到?这些网站数据是可以通过服务器的IIS日志可以获得。IIS日志上有记录网站在一个月内被访问的数据情况,无论是搜索引擎还是客户,只要访问了网站,就会被IIS日志记录下来。IIS日志上记录着用户与搜索引擎的访问路径,访问时间,访问的内容,以及访问时返回的反馈码。
作为一个合格的网站优化或者网站维护人员,通过IIS日志分析网站健康状况是必须会的技能。
网络服务器如IIS、Apache,会把每一个访问信息、服务器动作、文件调用自动记录下来,存放在原始日志文件里。日志文件是相对准确且全面的。
一般的流量信息工具上,一些重要的关于SEO的信息可能没有显示出来,只能通过查看日志,如蜘蛛爬行记录、服务器返回状态等。
今天,小小课堂网来给大家介绍如何进行IIS网站日志分析详解。希望本次的SEO教程对大家所有帮助。

从小小课堂网的2018年3月9日的日志中选取一段,我们来进行分析。
2018-03-09 01:06:49 172.19.90.134 GET
/1189 – 80 – 175.146.106.193 Mozilla/5.0+
(Linux;+U;+Android+6.0.1;+zh-cn;+OPPO
+A57+Build/MMB29M)+AppleWebKit/537.36+
(KHTML,+like+Gecko)+Version/4.0+
Chrome/53.0.2785.134+Mobile+Safari/537.36+
OppoBrowser/4.5.2 https://yz.m.sm.cn/s?q=
%E9%87%91%E5%B1%B1ocr%E8%AF%
86%E5%88%AB%E5%B7%A5%E5%
85%B7%E7%9B%AE%E5%89%8D%
E6%94%AF%E6%8C%81%E4%BB%
8E%E5%93%AA%E9%87%8C%E8%
AF%86%E5%88%AB%E6%96%87%E4%
BB%B6&from=
wy836274&by=submit&snum=0 200 0 0 1390
1、访问时间
2018-03-09 01:06:49
2、本地获取页面
172.19.90.134是服务器本地IP地址,如下图所示。

3、get获取网页地址
GET/1189获取域名下 /1189 这个地址,也就是www.xxkt.org/1189
GET,为服务器的通常的动作,也就是从服务器上获取某个文件,可以是HTML、图片、CSS等。
另外一种形式为POST,一般用于CGI脚本。
PS:CGI 意思为 Common Gateway Interface, 一种基于浏览器的输入、在Web服务器上运行的程序方法。

4、80端口
-80 指服务器的80端口。
5、访客IP地址
175.146.106.193 百度搜索IP显示:辽宁省鞍山市 联通

6、访客浏览器和设备信息
Mozilla/5.0+(Linux;+U;+Android+6.0.1;
+zh-cn;+OPPO+A57+Build/MMB29M)+
AppleWebKit/537.36+KHTML,+like+Gecko)+
Version/4.0+Chrome/53.0.2785.134+Mobile+
Safari/537.36+OppoBrowser/4.5.2
这段英文显示的是浏览器和访客设备信息。如OPPO A57手机、安卓系统、oppo浏览器等信息。
另外可能还会遇到:
360SE:360浏览器;
Firefox:火狐浏览器;
Chrome:Google浏览器。
Windows NT 5.1、Windows NT 6.1等指Windows NT操作系统,平时Windows XP、7、10均属于NT系列。
7、搜索引擎类别和搜索词
https://yz.m.sm.cn/ s?q=%E9%87%91%E5%B1%B1ocr%E8%AF%
86%E5%88%AB%E5%B7%A5%E5%85%B7%E7%9B
%AE%E5%89%8D%E6%94%AF%E6%8C%81%E4
%BB%8E%E5%93%AA%E9%87%8C%E8%AF%86%E5%
88%AB%E6%96%87%E4%BB%B6&from=wy836274
&by=submit&snum=0
这段话复制到浏览器中,则会显示如下图结果。
用户的搜索引擎:神马搜索。
用户的搜索词:金山ocr识别目前支持从哪里识别文件。

8、HTTP状态码正常
返回的HTTP状态为200,之前讲过200的含义为成功获取了文件,一切正常。其他常见HTTP状态码及其含义如下:
301:永久转向。
302:暂时转向。
304:文件未改变,客户端缓冲版本还可以继续使用。
400:非法请求。
401:访问被拒绝,需要用户名、密码。
403:禁止访问。
404:文件不存在或未找到。
500:服务器内部错误,通常是程序问题。
503:服务器没有应答,如负载过大等情况。
9、是否正常访问或抓取
HTTP200后面的0 0,表示文件被访客或者蜘蛛正常访问或抓取。
还有一种情况是 200 0 64 ,有的说是K站(这种说法被人骂的特别多,应该是错的),还有人说是64位系统(感觉不太靠谱),还有人说是开始GZIP压缩功能(那就先关了试试看),还有人说网站快照更新不及时(那就多发外链、多做友链、规律更新文章)。
10、花费时间
1390代表花费时间为1390毫秒。
上面那个字段就分析完了。
再来一个新的字段如下:
2018-03-09 00:40:51 172.19.90.134 GET
/1482 – 80 – 123.125.71.113 Mozilla/5.0+
(Linux;u;Android+4.2.2;zh-cn;)+
AppleWebKit/534.46+(KHTML,like+Gecko)+
Version/5.1+Mobile+Safari/10600.6.3+
(compatible;+Baiduspider/2.0;
++http://www.baidu.com/search/spider.html)
– 200 0 0 1312
2018-03-09 00:44:52 172.19.90.134
GET /about – 80 – 66.249.64.10 Mozilla/5.0+
(Linux;+Android+6.0.1;+Nexus+5X+
Build/MMB29P)+AppleWebKit/537.36+
(KHTML,+like+Gecko)+Chrome/41.0.2272.96
+Mobile+Safari/537.36+(compatible;
+Googlebot/2.1;++http://www.google.com/bot.html)
– 200 0 0 1671
11、搜索引擎蜘蛛
+Baiduspider/2.0;++http://www.baidu.com/search/spider.html表明自己身份是,百度搜索引擎蜘蛛。
+Googlebot/2.1;++http://www.google.com/bot.html表明自己身份是,Google机器人(Googlebot)。
类似的还有360spider(360搜索)、bingbot(必应搜索)、Sogou web spider(搜狗)。
还有一个比较有意思的蜘蛛叫做YisouSpider,属于神马搜索。网上有个观点是屏蔽神马蜘蛛,很多站长说,神马蜘蛛一个小时访问次数高达一万次,故网上出现了很多教程屏蔽神马蜘蛛。
灬无言刚检查了小小课堂网的一个日志,神马蜘蛛的访问也是非常正常的,可见并非所有的网站都需要屏蔽神马蜘蛛,百度词条上说,如果网站更新频率高,内容质量高,YisouSpider可能会非正常抓取,会导致服务器问题,需要尽快向神马反馈。
不建议屏蔽YisouSpider,因为神马移动端的流量也是非常可观的。
12、日志参数如何自定义
其实,这些日志中,有些未被记录,需要我们调整出来,或者将不想看到的日志参数取消记录,从哪里寻找呢?
1)打开IIS服务器,点击左侧网站后,在右侧点击“日志”。

2)点击选择字段。

3)可选字段,如发送的字节数、接收的字节数、协议版本、主机等。

13、如何查看这些杂乱无章的日志
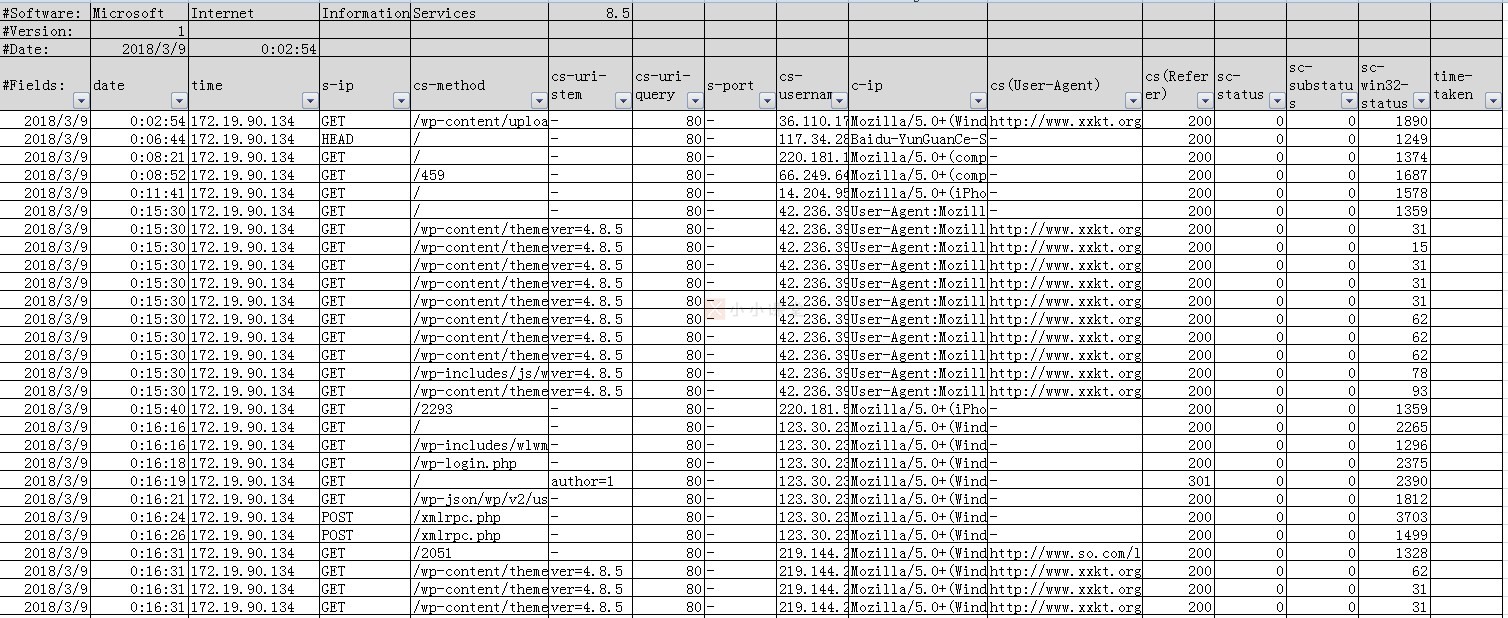
小小课堂网其中一个日志用文本文档打开如下图所示。估计谁看了都头疼吧。
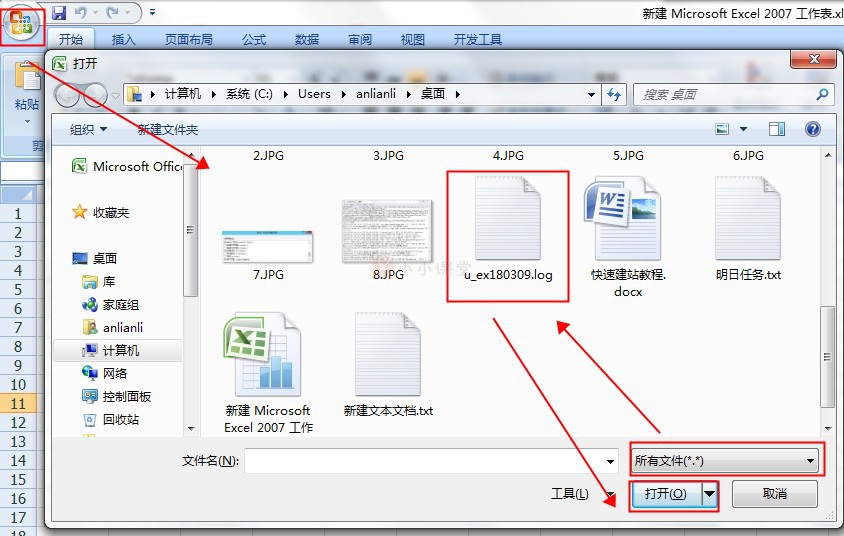
方法1:用Excel表打开日志的txt文件。
a)新建并打开Excel文件。
b)用Excel文件打开.log的日志文件,打开时,又下角选择“全部文件(*.*)”,不然是看不到.log文件的。
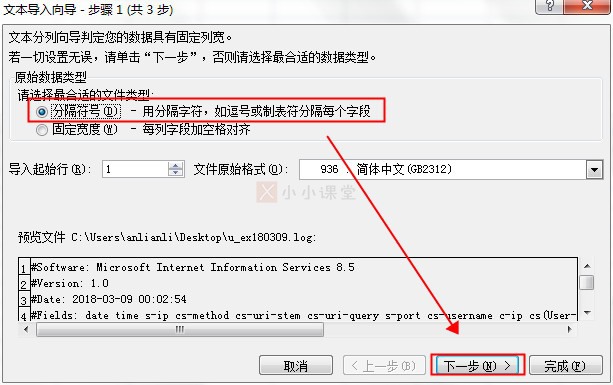
c)打开后,选择“分隔符号”,然后下一步。
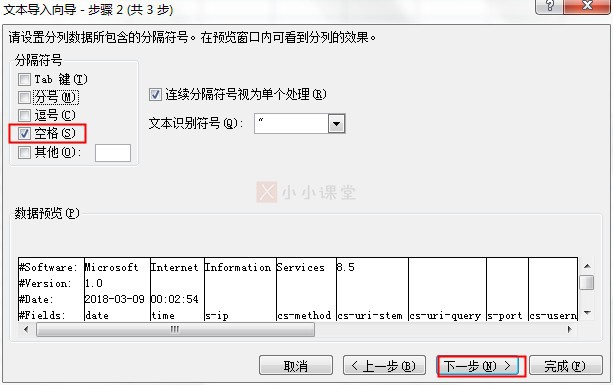
d)选择分隔符号为“空格”。然后下一步。
e)格式按需选择,一般默认也可以。
f)最后简单将上述标签单元格换个“背景色”,将标签单元格“自动换行”外加“筛选”,就可以做数据的简单统计了,或者插入数据透视表。是不是比单纯的txt文档看起来舒服多啦。
14、日志分析软件
如果上述日志分析方法不能满足您的日常需求,那么专业的日志分析软件就是您最后的选择啦。关注本站,后期会推荐几款日志分析软件。
本文章转自小小课堂SEO自学网https://www.xxkt.org/2639/




